Features of Databricks Databricks-Generative-AI-Engineer-Associate Dumps PDF Format
Wiki Article
BONUS!!! Download part of Test4Sure Databricks-Generative-AI-Engineer-Associate dumps for free: https://drive.google.com/open?id=1FWSL1vIIZwcFsFBYev5Eeef6mxQWKJWo
The Databricks-Generative-AI-Engineer-Associate study guide in order to allow the user to form a complete system of knowledge structure, the qualification Databricks-Generative-AI-Engineer-Associate examination of test interpretation and supporting course practice organic reasonable arrangement together, the Databricks-Generative-AI-Engineer-Associate simulating materials let the user after learning the section of the new curriculum can through the way to solve the problem to consolidate, and each section between cohesion and is closely linked, for users who use the Databricks-Generative-AI-Engineer-Associate Exam Prep to build a knowledge of logical framework to create a good condition.
Our team of experts updates actual Databricks Databricks-Generative-AI-Engineer-Associate questions regularly so you can prepare for the Databricks-Generative-AI-Engineer-Associate exam according to the latest copyright. Additionally, we also offer up to 1 year of free Databricks-Generative-AI-Engineer-Associate exam questions updates. We have a 24/7 customer service team available for your assistance if you get stuck somewhere. Buy Databricks-Generative-AI-Engineer-Associate Latest Questions of Test4Sure now and get ready to crack the Databricks-Generative-AI-Engineer-Associate certification exam in a single attempt.
>> Latest Databricks-Generative-AI-Engineer-Associate Exam Price <<
Practical Databricks-Generative-AI-Engineer-Associate Information | Databricks-Generative-AI-Engineer-Associate Valid copyright Ebook
Our Databricks-Generative-AI-Engineer-Associate study materials are famous at home and abroad, the main reason is because we have other companies that do not have core competitiveness, there are many complicated similar products on the market, if you want to stand out is the selling point of needs its own. Our Databricks-Generative-AI-Engineer-Associate Study Materials with other product of different thing is we have the most core expert team to update our Databricks-Generative-AI-Engineer-Associate study materials , learning platform to changes with the change of the exam outline.
Databricks Databricks-Generative-AI-Engineer-Associate Exam copyright Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
Databricks Certified Generative AI Engineer Associate Sample Questions (Q33-Q38):
NEW QUESTION # 33
A company has a typical RAG-enabled, customer-facing chatbot on its website.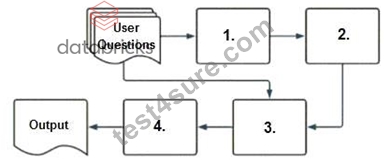
Select the correct sequence of components a user's questions will go through before the final output is returned. Use the diagram above for reference.
- A. 1.context-augmented prompt, 2.vector search, 3.embedding model, 4.response-generating LLM
- B. 1.embedding model, 2.vector search, 3.context-augmented prompt, 4.response-generating LLM
- C. 1.response-generating LLM, 2.context-augmented prompt, 3.vector search, 4.embedding model
- D. 1.response-generating LLM, 2.vector search, 3.context-augmented prompt, 4.embedding model
Answer: B
Explanation:
To understand how a typical RAG-enabled customer-facing chatbot processes a user's question, let's go through the correct sequence as depicted in the diagram and explained in option A:
* Embedding Model (1):The first step involves the user's question being processed through an embedding model. This model converts the text into a vector format that numerically represents the text. This step is essential for allowing the subsequent vector search to operate effectively.
* Vector Search (2):The vectors generated by the embedding model are then used in a vector search mechanism. This search identifies the most relevant documents or previously answered questions that are stored in a vector format in a database.
* Context-Augmented Prompt (3):The information retrieved from the vector search is used to create a context-augmented prompt. This step involves enhancing the basic user query with additional relevant information gathered to ensure the generated response is as accurate and informative as possible.
* Response-Generating LLM (4):Finally, the context-augmented prompt is fed into a response- generating large language model (LLM). This LLM uses the prompt to generate a coherent and contextually appropriate answer, which is then delivered as the final output to the user.
Why Other Options Are Less Suitable:
* B, C, D: These options suggest incorrect sequences that do not align with how a RAG system typically processes queries. They misplace the role of embedding models, vector search, and response generation in an order that would not facilitate effective information retrieval and response generation.
Thus, the correct sequence isembedding model, vector search, context-augmented prompt, response- generating LLM, which is option A.
NEW QUESTION # 34
A team uses Mosaic AI Vector Search to retrieve documents for their Retrieval-Augmented Generation (RAG) pipeline. The search query returns five relevant documents, and the first three are added to the prompt as context. Performance evaluation with Agent Evaluation shows that some lower-ranked retrieved documents have higher context relevancy scores than higher-ranked documents. Which option should the team consider to optimize this workflow?
- A. Modify the prompt to instruct the LLM to order the documents based on the relevance scores.
- B. Increase the number of documents added to the prompt to improve context relevance.
- C. Use a different embedding model for computing document embeddings.
- D. Use a reranker to order the documents based on the relevance scores.
Answer: D
Explanation:
The scenario describes a common "retrieval gap" where the initial bi-encoder (embedding model) used for vector search identifies relevant documents but does not rank them perfectly. This happens because embedding models represent entire documents as a single vector, which can lose nuance. The standard engineering solution is to implement a Reranker (Cross-Encoder). Unlike embedding models, a reranker processes the query and a candidate document simultaneously, allowing it to capture deep semantic interactions between the two. In a Mosaic AI workflow, after the vector search retrieves the top $k$ documents, the reranker evaluates those specific $k$ documents to produce a more accurate relevance score. This ensures that the most contextually relevant documents are placed at the top of the list (and thus the top of the LLM prompt), which is crucial because LLMs are sensitive to document order and often prioritize information found at the beginning of the context.
NEW QUESTION # 35
A Generative AI Engineer is designing a RAG application for answering user questions on technical regulations as they learn a new sport.
What are the steps needed to build this RAG application and deploy it?
- A. Ingest documents from a source -> Index the documents and saves to Vector Search -> User submits queries against an LLM -> LLM retrieves relevant documents -> Evaluate model -> LLM generates a response -> Deploy it using Model Serving
- B. User submits queries against an LLM -> Ingest documents from a source -> Index the documents and save to Vector Search -> LLM retrieves relevant documents -> LLM generates a response -> Evaluate model -> Deploy it using Model Serving
- C. Ingest documents from a source -> Index the documents and save to Vector Search -> User submits queries against an LLM -> LLM retrieves relevant documents -> LLM generates a response -> Evaluate model -> Deploy it using Model Serving
- D. Ingest documents from a source -> Index the documents and save to Vector Search -> Evaluate model -
> Deploy it using Model Serving
Answer: C
Explanation:
The Generative AI Engineer needs to follow a methodical pipeline to build and deploy a Retrieval- Augmented Generation (RAG) application. The steps outlined in optionBaccurately reflect this process:
* Ingest documents from a source: This is the first step, where the engineer collects documents (e.g., technical regulations) that will be used for retrieval when the application answers user questions.
* Index the documents and save to Vector Search: Once the documents are ingested, they need to be embedded using a technique like embeddings (e.g., with a pre-trained model like BERT) and stored in a vector database (such as Pinecone or FAISS). This enables fast retrieval based on user queries.
* User submits queries against an LLM: Users interact with the application by submitting their queries.
These queries will be passed to the LLM.
* LLM retrieves relevant documents: The LLM works with the vector store to retrieve the most relevant documents based on their vector representations.
* LLM generates a response: Using the retrieved documents, the LLM generates a response that is tailored to the user's question.
* Evaluate model: After generating responses, the system must be evaluated to ensure the retrieved documents are relevant and the generated response is accurate. Metrics such as accuracy, relevance, and user satisfaction can be used for evaluation.
* Deploy it using Model Serving: Once the RAG pipeline is ready and evaluated, it is deployed using a model-serving platform such as Databricks Model Serving. This enables real-time inference and response generation for users.
By following these steps, the Generative AI Engineer ensures that the RAG application is both efficient and effective for the task of answering technical regulation questions.
NEW QUESTION # 36
A Generative Al Engineer is working with a retail company that wants to enhance its customer experience by automatically handling common customer inquiries. They are working on an LLM-powered Al solution that should improve response times while maintaining a personalized interaction. They want to define the appropriate input and LLM task to do this.
Which input/output pair will do this?
- A. Input: Customer reviews: Output Classify review sentiment
- B. Input: Customer service chat logs; Output: Find the answers to similar questions and respond with a summary
- C. Input: Customer reviews; Output Group the reviews by users and aggregate per-user average rating, then respond
- D. Input: Customer service chat logs; Output Group the chat logs by users, followed by summarizing each user's interactions, then respond
Answer: B
Explanation:
The task described in the question involves enhancing customer experience by automatically handling common customer inquiries using an LLM-powered AI solution. This requires the system to process input data (customer inquiries) and generate personalized, relevant responses efficiently. Let's evaluate the options step-by-step in the context of Databricks Generative AI Engineer principles, which emphasize leveraging LLMs for tasks like question answering, summarization, and retrieval-augmented generation (RAG).
* Option A: Input: Customer reviews; Output: Group the reviews by users and aggregate per-user average rating, then respond
* This option focuses on analyzing customer reviews to compute average ratings per user. While this might be useful for sentiment analysis or user profiling, it does not directly address the goal of handling common customer inquiries or improving response times for personalized interactions. Customer reviews are typically feedback data, not real-time inquiries requiring immediate responses.
* Databricks Reference: Databricks documentation on LLMs (e.g., "Building LLM Applications with Databricks") emphasizes that LLMs excel at tasks like question answering and conversational responses, not just aggregation or statistical analysis of reviews.
* Option B: Input: Customer service chat logs; Output: Group the chat logs by users, followed by summarizing each user's interactions, then respond
* This option uses chat logs as input, which aligns with customer service scenarios. However, the output-grouping by users and summarizing interactions-focuses on user-specific summaries rather than directly addressing inquiries. While summarization is an LLM capability, this approach lacks the specificity of finding answers to common questions, which is central to the problem.
* Databricks Reference: Per Databricks' "Generative AI Cookbook," LLMs can summarize text, but for customer service, the emphasis is on retrieval and response generation (e.g., RAG workflows) rather than user interaction summaries alone.
* Option C: Input: Customer service chat logs; Output: Find the answers to similar questions and respond with a summary
* This option uses chat logs (real customer inquiries) as input and tasks the LLM with identifying answers to similar questions, then providing a summarized response. This directly aligns with the goal of handling common inquiries efficiently while maintaining personalization (by referencing past interactions or similar cases). It leverages LLM capabilities like semantic search, retrieval, and response generation, which are core to Databricks' LLM workflows.
* Databricks Reference: From Databricks documentation ("Building LLM-Powered Applications," 2023), an exact extract states:"For customer support use cases, LLMs can be used to retrieve relevant answers from historical data like chat logs and generate concise, contextually appropriate responses."This matches Option C's approach of finding answers and summarizing them.
* Option D: Input: Customer reviews; Output: Classify review sentiment
* This option focuses on sentiment classification of reviews, which is a valid LLM task but unrelated to handling customer inquiries or improving response times in a conversational context.
It's more suited for feedback analysis than real-time customer service.
* Databricks Reference: Databricks' "Generative AI Engineer Guide" notes that sentiment analysis is a common LLM task, but it's not highlighted for real-time conversational applications like customer support.
Conclusion: Option C is the best fit because it uses relevant input (chat logs) and defines an LLM task (finding answers and summarizing) that meets the requirements of improving response times and maintaining personalized interaction. This aligns with Databricks' recommended practices for LLM-powered customer service solutions, such as retrieval-augmented generation (RAG) workflows.
NEW QUESTION # 37
Which TWO chain components are required for building a basic LLM-enabled chat application that includes conversational capabilities, knowledge retrieval, and contextual memory?
- A. Conversation Buffer Memory
- B. Chat loaders
- C. (Q)
- D. External tools
- E. Vector Stores
- F. React Components
Answer: A,E
Explanation:
Building a basic LLM-enabled chat application with conversational capabilities, knowledge retrieval, and contextual memory requires specific components that work together to process queries, maintain context, and retrieve relevant information. Databricks' Generative AI Engineer documentation outlines key components for such systems, particularly in the context of frameworks like LangChain or Databricks' MosaicML integrations. Let's evaluate the required components:
* Understanding the Requirements:
* Conversational capabilities: The app must generate natural, coherent responses.
* Knowledge retrieval: It must access external or domain-specific knowledge.
* Contextual memory: It must remember prior interactions in the conversation.
* Databricks Reference:"A typical LLM chat application includes a memory component to track conversation history and a retrieval mechanism to incorporate external knowledge"("Databricks Generative AI Cookbook," 2023).
* Evaluating the Options:
* A. (Q): This appears incomplete or unclear (possibly a typo). Without further context, it's not a valid component.
* B. Vector Stores: These store embeddings of documents or knowledge bases, enabling semantic search and retrieval of relevant information for the LLM. This is critical for knowledge retrieval in a chat application.
* Databricks Reference:"Vector stores, such as those integrated with Databricks' Lakehouse, enable efficient retrieval of contextual data for LLMs"("Building LLM Applications with Databricks").
* C. Conversation Buffer Memory: This component stores the conversation history, allowing the LLM to maintain context across multiple turns. It's essential for contextual memory.
* Databricks Reference:"Conversation Buffer Memory tracks prior user inputs and LLM outputs, ensuring context-aware responses"("Generative AI Engineer Guide").
* D. External tools: These (e.g., APIs or calculators) enhance functionality but aren't required for a basicchat app with the specified capabilities.
* E. Chat loaders: These might refer to data loaders for chat logs, but they're not a core chain component for conversational functionality or memory.
* F. React Components: These relate to front-end UI development, not the LLM chain's backend functionality.
* Selecting the Two Required Components:
* Forknowledge retrieval, Vector Stores (B) are necessary to fetch relevant external data, a cornerstone of Databricks' RAG-based chat systems.
* Forcontextual memory, Conversation Buffer Memory (C) is required to maintain conversation history, ensuring coherent and context-aware responses.
* While an LLM itself is implied as the core generator, the question asks for chain components beyond the model, making B and C the minimal yet sufficient pair for a basic application.
Conclusion: The two required chain components areB. Vector StoresandC. Conversation Buffer Memory, as they directly address knowledge retrieval and contextual memory, respectively, aligning with Databricks' documented best practices for LLM-enabled chat applications.
NEW QUESTION # 38
......
When preparing to take the Databricks Databricks-Generative-AI-Engineer-Associate exam dumps, knowing where to start can be a little frustrating, but with Test4Sure Databricks Databricks-Generative-AI-Engineer-Associate practice questions, you will feel fully prepared. Using our Databricks Databricks-Generative-AI-Engineer-Associate practice test software, you can prepare for the increased difficulty on Databricks-Generative-AI-Engineer-Associate Exam day. Plus, we have various question types and difficulty levels so that you can tailor your Databricks Databricks-Generative-AI-Engineer-Associate exam dumps preparation to your requirements.
Practical Databricks-Generative-AI-Engineer-Associate Information: https://www.test4sure.com/Databricks-Generative-AI-Engineer-Associate-pass4sure-vce.html
- New Latest Databricks-Generative-AI-Engineer-Associate Exam Price 100% Pass | Valid Practical Databricks-Generative-AI-Engineer-Associate Information: Databricks Certified Generative AI Engineer Associate ???? Search on ⏩ www.prep4away.com ⏪ for ➡ Databricks-Generative-AI-Engineer-Associate ️⬅️ to obtain exam materials for free download ????Related Databricks-Generative-AI-Engineer-Associate Certifications
- Valid Latest Databricks-Generative-AI-Engineer-Associate Exam Price - Authoritative Source of Databricks-Generative-AI-Engineer-Associate Exam ???? Copy URL ▷ www.pdfvce.com ◁ open and search for ➽ Databricks-Generative-AI-Engineer-Associate ???? to download for free ????Databricks-Generative-AI-Engineer-Associate Pdf copyright
- Free PDF Quiz Databricks - Databricks-Generative-AI-Engineer-Associate - Newest Latest Databricks Certified Generative AI Engineer Associate Exam Price ???? ⇛ www.prepawayexam.com ⇚ is best website to obtain ▷ Databricks-Generative-AI-Engineer-Associate ◁ for free download ????Databricks-Generative-AI-Engineer-Associate Test Duration
- Valid Latest Databricks-Generative-AI-Engineer-Associate Exam Price - Authoritative Source of Databricks-Generative-AI-Engineer-Associate Exam ???? Search for { Databricks-Generative-AI-Engineer-Associate } and download it for free immediately on 【 www.pdfvce.com 】 ✳Databricks-Generative-AI-Engineer-Associate Study Test
- 100% Pass Databricks-Generative-AI-Engineer-Associate - Databricks Certified Generative AI Engineer Associate Fantastic Latest Exam Price ???? Easily obtain ➠ Databricks-Generative-AI-Engineer-Associate ???? for free download through ⏩ www.vce4dumps.com ⏪ ????Reliable Databricks-Generative-AI-Engineer-Associate Dumps Free
- Databricks-Generative-AI-Engineer-Associate Pdf copyright ???? Databricks-Generative-AI-Engineer-Associate Valid Exam Test ⏲ Valid Databricks-Generative-AI-Engineer-Associate Exam Bootcamp ???? Enter ⏩ www.pdfvce.com ⏪ and search for [ Databricks-Generative-AI-Engineer-Associate ] to download for free ????Related Databricks-Generative-AI-Engineer-Associate Certifications
- Databricks-Generative-AI-Engineer-Associate Latest copyright Free ⛑ Databricks-Generative-AI-Engineer-Associate Test Duration ???? Databricks-Generative-AI-Engineer-Associate Study Guides ???? Search for ➠ Databricks-Generative-AI-Engineer-Associate ???? on ➥ www.vce4dumps.com ???? immediately to obtain a free download ????Databricks-Generative-AI-Engineer-Associate Test Duration
- Free PDF Quiz Databricks - Databricks-Generative-AI-Engineer-Associate - Newest Latest Databricks Certified Generative AI Engineer Associate Exam Price ???? Copy URL ➥ www.pdfvce.com ???? open and search for ▛ Databricks-Generative-AI-Engineer-Associate ▟ to download for free ????Databricks-Generative-AI-Engineer-Associate Test Duration
- Databricks-Generative-AI-Engineer-Associate Pdf copyright ⏪ Databricks-Generative-AI-Engineer-Associate Download ???? Related Databricks-Generative-AI-Engineer-Associate Certifications ???? Search for ➥ Databricks-Generative-AI-Engineer-Associate ???? and download exam materials for free through 《 www.exam4labs.com 》 ????Databricks-Generative-AI-Engineer-Associate Latest Test Experience
- New Latest Databricks-Generative-AI-Engineer-Associate Exam Price 100% Pass | Valid Practical Databricks-Generative-AI-Engineer-Associate Information: Databricks Certified Generative AI Engineer Associate ???? Download ✔ Databricks-Generative-AI-Engineer-Associate ️✔️ for free by simply searching on ➥ www.pdfvce.com ???? ????Databricks-Generative-AI-Engineer-Associate Certification Dumps
- Databricks-Generative-AI-Engineer-Associate Pdf copyright ???? Databricks-Generative-AI-Engineer-Associate Pdf copyright ???? Databricks-Generative-AI-Engineer-Associate Download ???? Easily obtain ➠ Databricks-Generative-AI-Engineer-Associate ???? for free download through ⇛ www.prep4sures.top ⇚ ????Databricks-Generative-AI-Engineer-Associate Certification Dumps
- thejillist.com, charlieclrc303357.blogproducer.com, kidoola.com.my, easiestbookmarks.com, abelevlb537890.fliplife-wiki.com, www.stes.tyc.edu.tw, asiyajmny024160.prublogger.com, arranpnvp140652.iyublog.com, pennyxeux421522.levitra-wiki.com, keybookmarks.com, Disposable vapes
P.S. Free 2026 Databricks Databricks-Generative-AI-Engineer-Associate dumps are available on Google Drive shared by Test4Sure: https://drive.google.com/open?id=1FWSL1vIIZwcFsFBYev5Eeef6mxQWKJWo
Report this wiki page